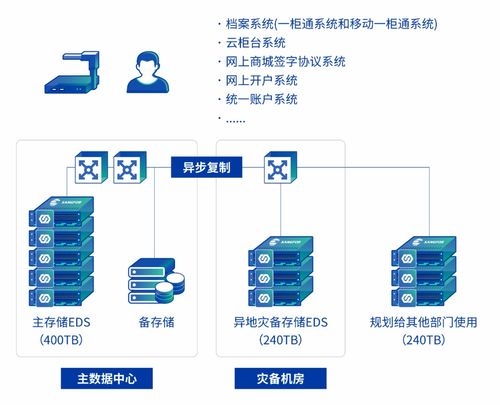
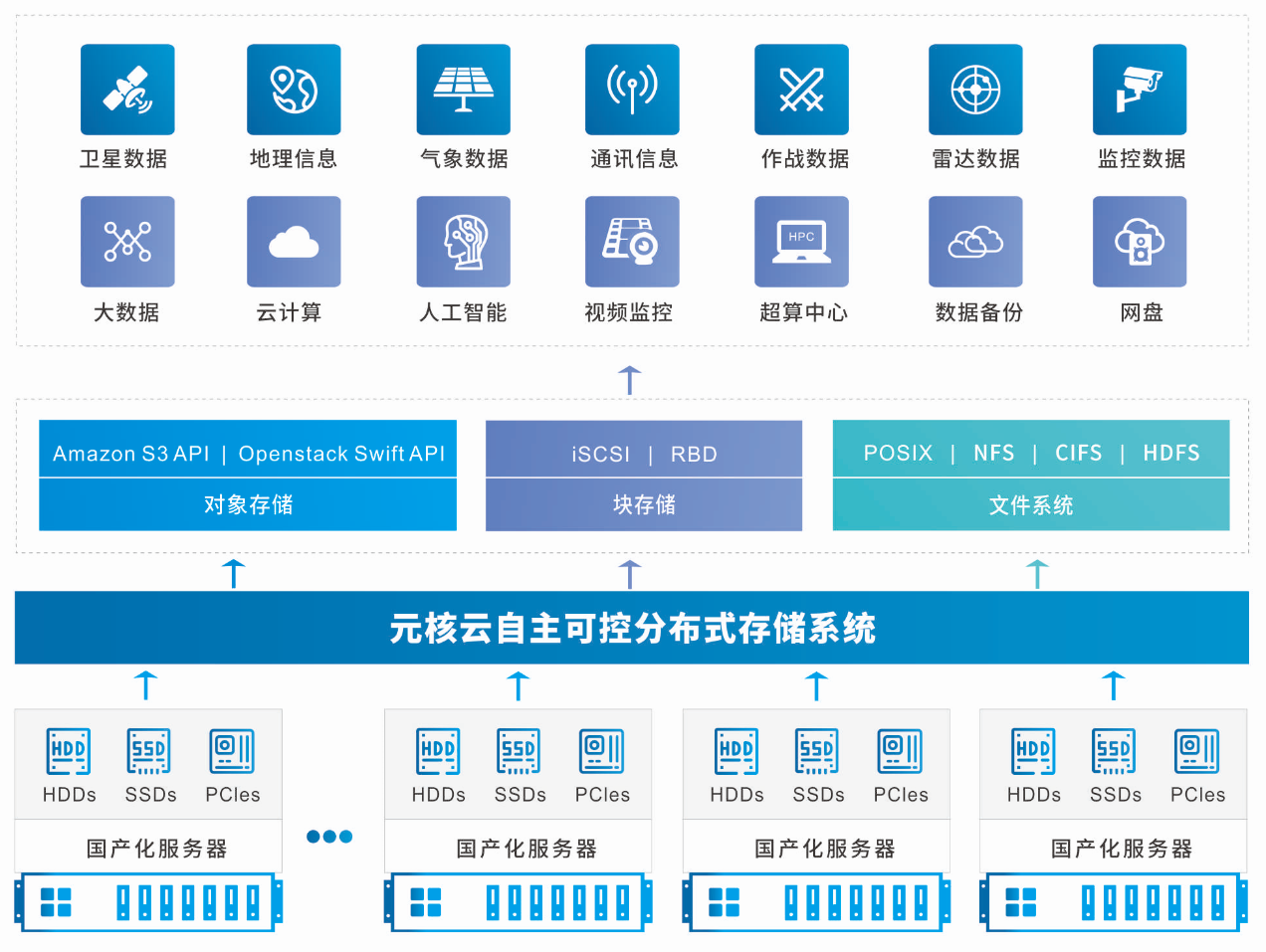
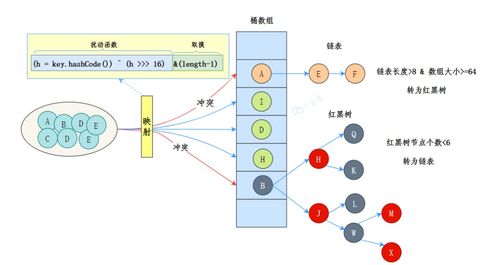
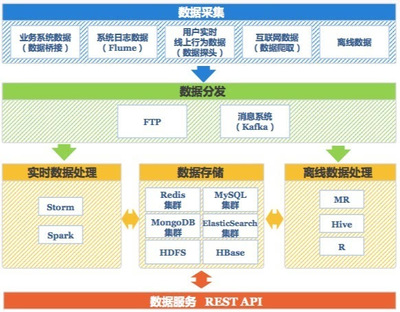
Druid 引领实时数据分析的新一代存储与计算引擎
在大数据时代,数据的价值往往与处理速度直接相关。传统的批处理系统虽然能够处理海量数据,但其固有的延迟无法满足实时监控、交互式查询和即时决策等场景的迫切需求。在此背景下,Apache Druid应运而生,它作为一个开源的、分布式的、面向列的数据存储系统,专门为需要实时数据摄取、低延迟查询和高可用性的应用场景而设计。本文将深入解析Druid作为实时数据分析存储系统的核心数据处理与存储支持服务。
一、核心定位:为实时分析而生
Druid的设计哲学是融合数据仓库、时间序列数据库和搜索系统的优势。它不是一个通用的OLTP数据库,而是专注于OLAP(在线分析处理)场景,特别是那些需要亚秒级查询响应的实时数据分析。无论是网站点击流分析、广告技术平台、网络性能监控,还是物联网传感器数据分析,Druid都能提供强大的支持。
二、数据处理能力:实时与批处理的无缝融合
Druid的数据处理架构是其强大能力的基石,主要体现在数据摄取和查询处理两个层面。
1. 实时数据摄取(流式摄入):
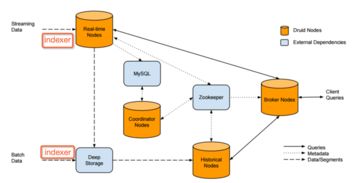
Druid能够直接从消息队列(如Kafka、Kinesis)中持续摄取数据流,实现近乎实时的数据可见性。其“实时节点”负责消费流数据,并构建成内存中的索引片段,随后定期将这些片段持久化到深度存储中,并移交历史节点管理。这个过程确保了数据从产生到可查询的延迟极低。
2. 批处理数据摄取:
对于存储在HDFS、亚马逊S3等数据湖中的历史数据或批量数据,Druid同样支持高效地批量导入。这实现了实时流数据与历史批数据的统一存储和查询,用户可以用同一种查询语言分析所有数据。
3. 查询处理:
Druid使用基于JSON的查询语言,并支持SQL(通过内置的Avatica JDBC驱动或专门的SQL层)。其查询引擎专为快速聚合和扫描优化。当查询到达时,协调节点会将查询路由到相关的数据节点(历史节点和实时节点),各节点并行处理本地数据(利用列式存储和位图索引进行快速过滤和聚合),中间结果再由代理节点或查询节点汇总返回给用户,整个过程通常在毫秒到秒级完成。
三、存储支持服务:为高性能查询设计的架构
Druid的存储架构是其实现低延迟查询和高吞吐量的关键。
1. 列式存储:
Druid按列存储数据。这种格式对于分析型查询极其高效,因为查询通常只涉及部分列。只需读取查询所需的列,极大地减少了磁盘I/O,提高了扫描和聚合速度。
2. 分布式架构与数据分片:
Druid是分布式系统,数据被自动分割成多个“段”。每个“段”是一个独立的数据单元,包含了某个时间区间内的数据,并进行了压缩和索引。这些段被分散在集群的历史节点上,实现了数据的分布式存储和并行处理能力。
- 多层索引结构:
- 位图索引: 对于维度列,Druid会创建位图索引,可以极其快速地进行等值过滤和分组操作。
- 倒排索引: 支持高效的搜索式查询。
- 时间索引: 数据默认按时间分区,查询可以快速定位到特定时间范围的段,这是时间序列分析的天然优化。
- 压缩编码: 根据列的数据类型(如字符串、数值)应用不同的压缩算法(如字典编码、游程编码),减少存储空间和内存占用。
4. 深度存储与容错性:
Druid采用存储与计算分离的设计。处理好的数据“段”会持久化到一个共享的、高可用的“深度存储”系统中(如S3、HDFS、Azure Blob)。计算节点(历史节点)从深度存储加载段到本地进行查询服务。这种设计使得计算节点可以无状态地扩展和故障恢复:如果一个历史节点宕机,协调节点可以指挥另一个节点从深度存储重新加载其负责的段,从而保证了系统的高可用性。
5. 预聚合(Roll-up):
在数据摄取阶段,Druid支持可选的数据预聚合。它可以在摄入时根据指定的维度集合对数据进行汇总,丢弃原始数据,只保留聚合后的结果。这能显著减少数据存储量,并极大提升对固定维度组合的查询性能,是应对超大规模数据集的利器。
四、生态系统与集成
Druid拥有活跃的生态系统,可以轻松与主流的大数据工具集成。它支持从Kafka、Flume、Spark、Flink等系统摄入数据;可以通过Grafana、Superset、Tableau等可视化工具进行数据展示;其SQL接口也使其易于被熟悉传统数据库的分析师使用。
###
Apache Druid通过其独特的数据处理和存储架构,在实时数据分析领域占据了重要地位。它将实时流处理、高效列式存储、分布式计算和强大的索引能力融为一体,为需要快速洞察海量时序数据的应用提供了一个强大、可扩展且高可用的解决方案。无论是构建实时业务仪表盘、进行用户行为分析,还是监控复杂的基础设施,Druid都是一个值得深入研究和采用的核心技术组件。
如若转载,请注明出处:http://www.opulencespring.com/product/65.html
更新时间:2026-06-19 00:44:15